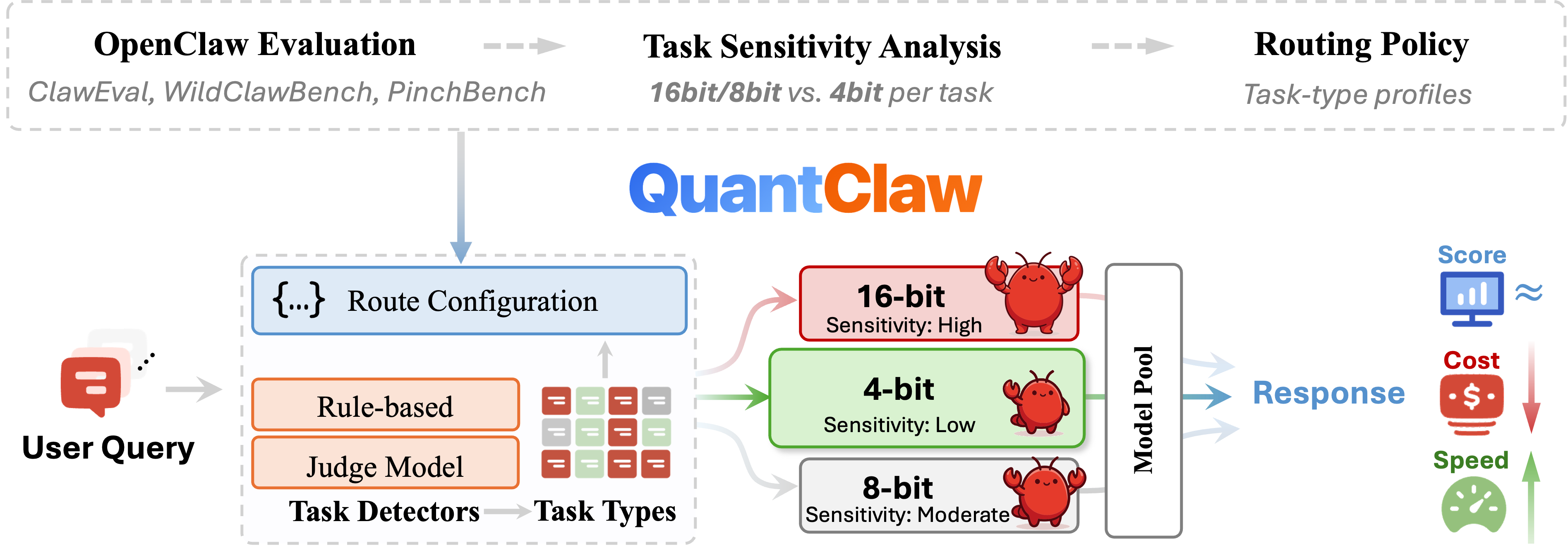
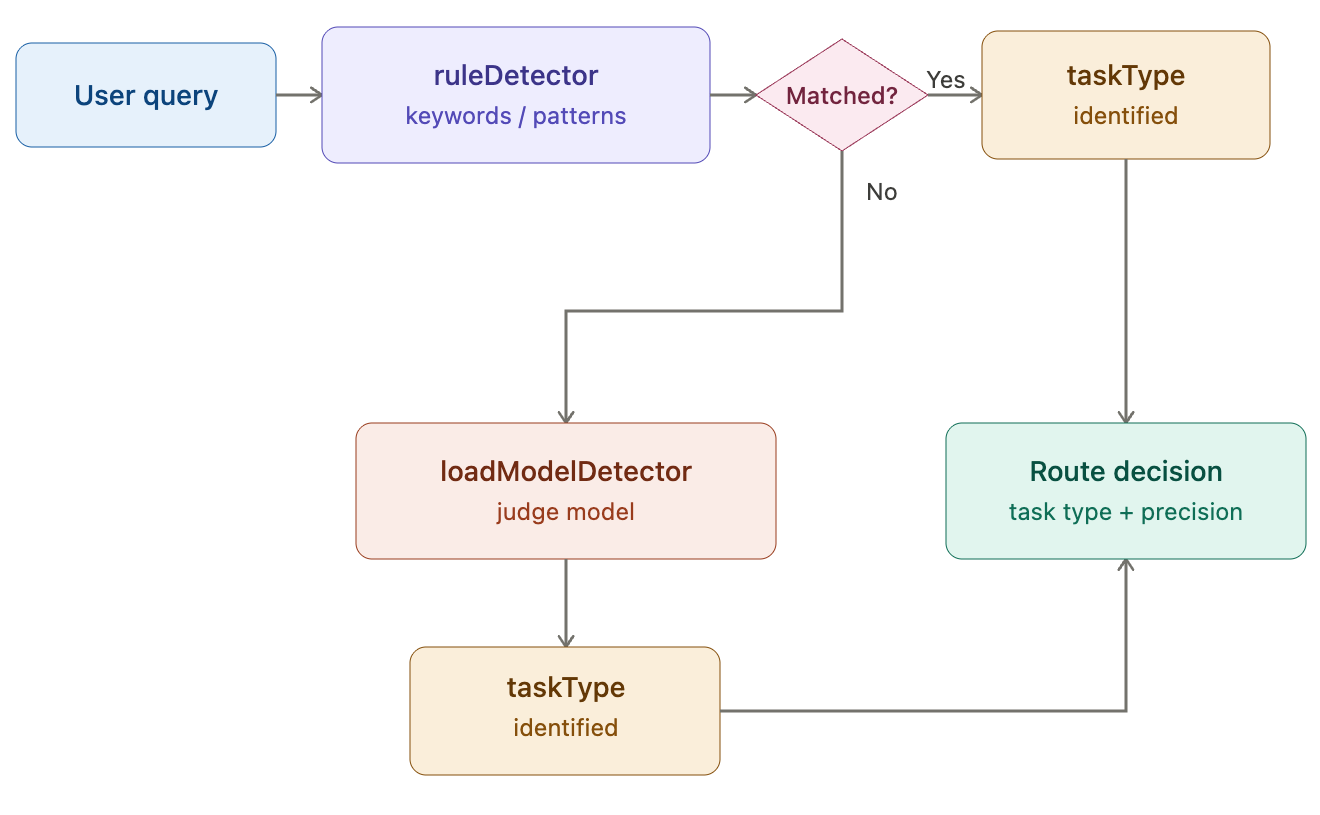
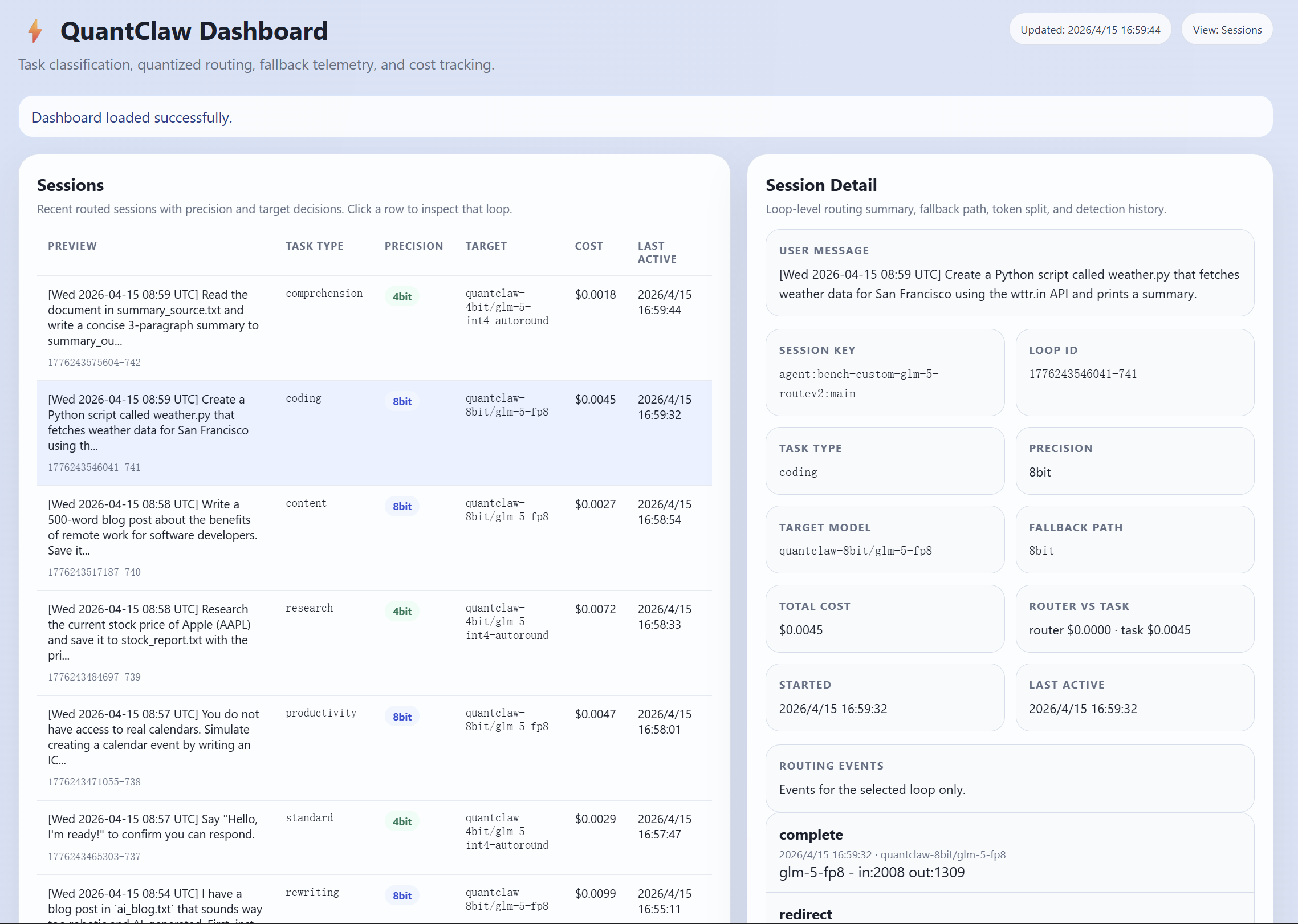
However, this capability comes at a steep token cost. Even a seemingly simple query can trigger far more than a single response, as OpenClaw often has to carry long system prompts, conversation history, tool outputs, and multi-step reasoning into each API call. In practice, users are paying not only for the answer itself, but for the overhead of running a full agent system.
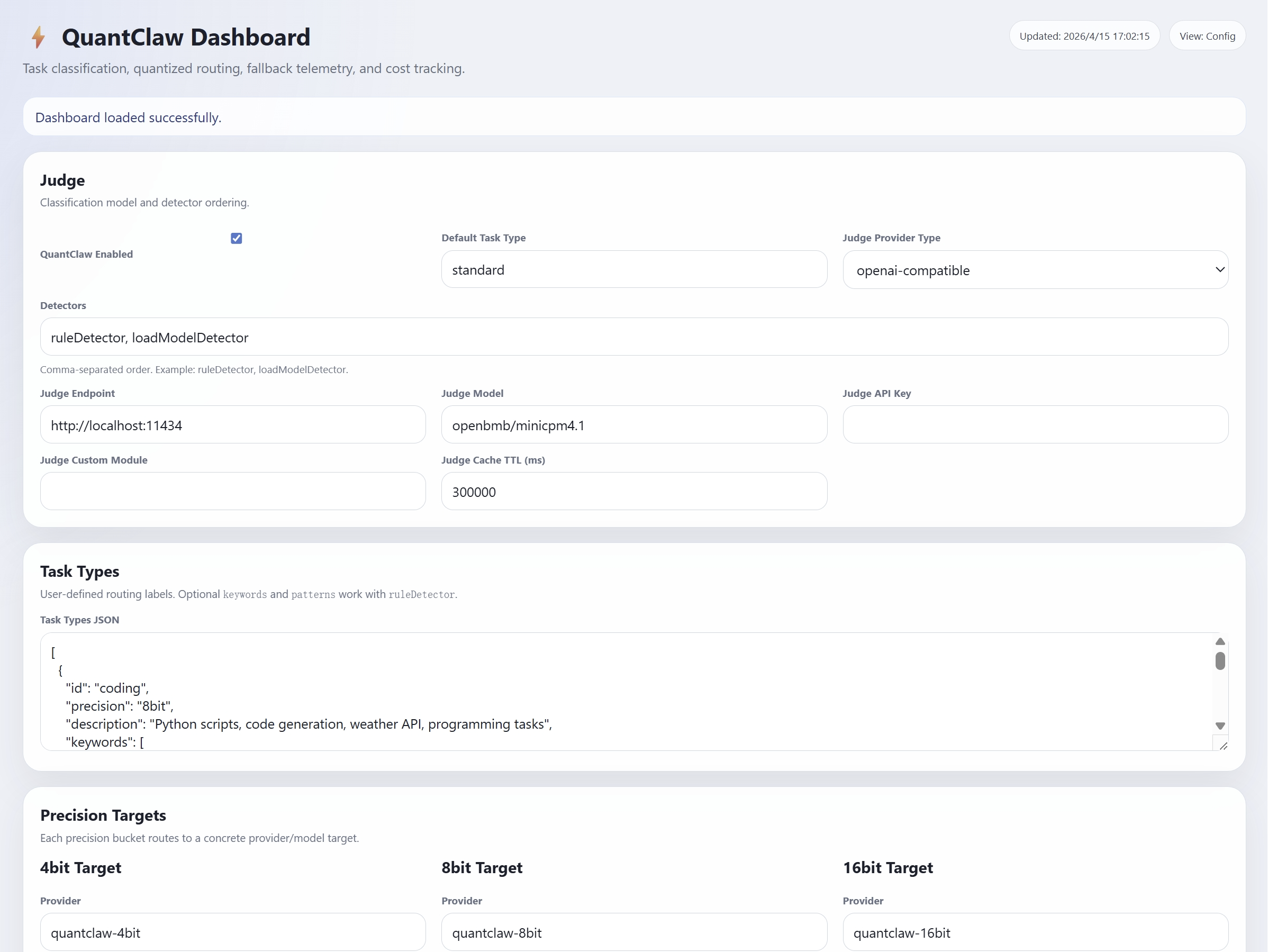
Model quantization can make models cheaper and faster to run. By reducing numerical precision from 32-bit floats down to 4-bit or even 2-bit, quantization can dramatically shrink memory footprint and compute. However, its effect on agentic tasks remains unclear, motivating the following questions:
Research Questions
(1) How does quantization affect OpenClaw overall?
(2) How does its impact vary across different task types?
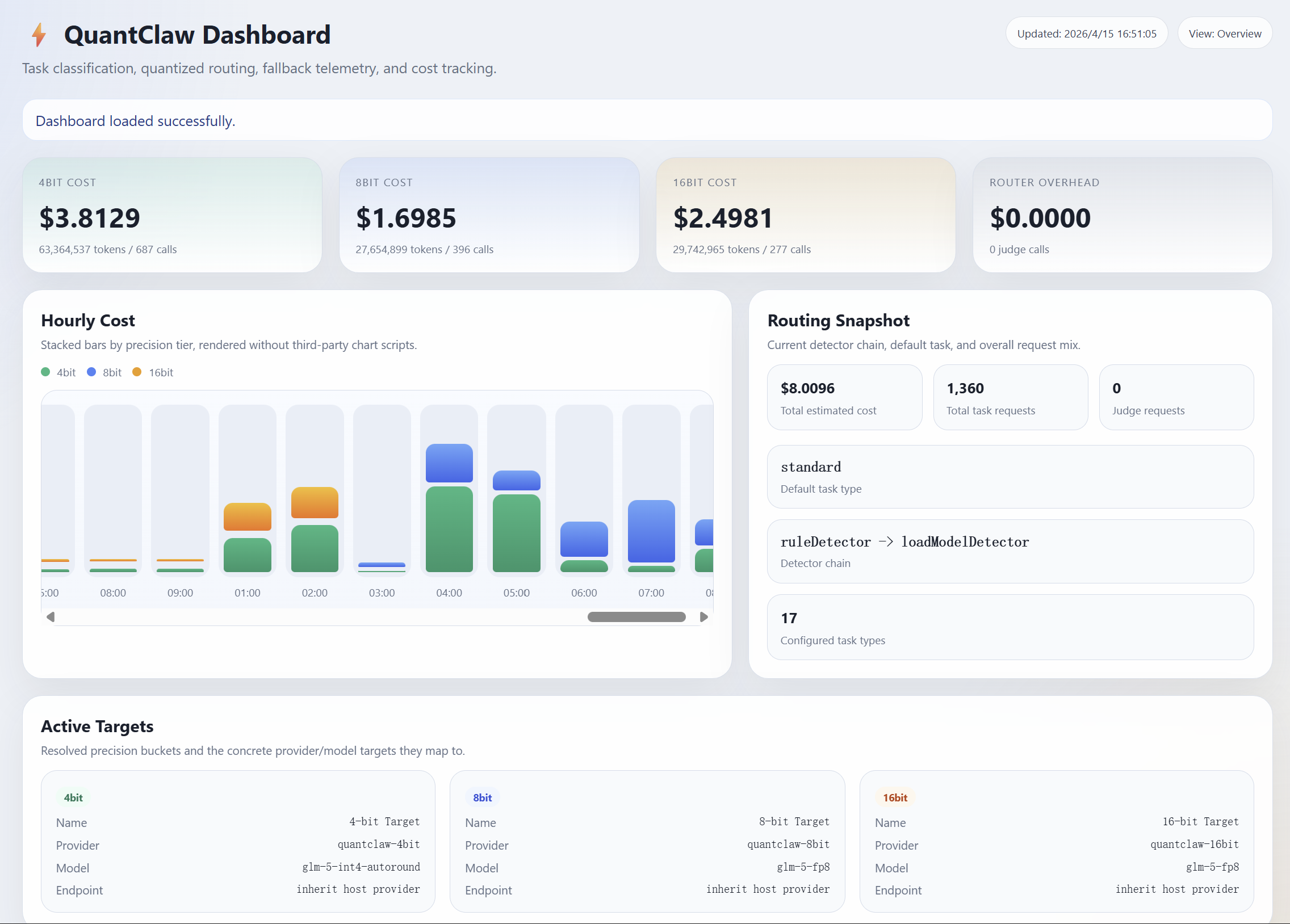
(3) How much cost can we actually save and how much speedup can we achieve in practice through quantization?